HTML解析,构建DOM
整个渲染步骤中,HTML解析是第一步。
简单的理解,这一步的流程是这样的:浏览器解析HTML,构建DOM树。
但实际上,在分析整体构建时,却不能一笔带过,得稍微展开。
解析HTML到构建出DOM当然过程可以简述如下:
Bytes → characters → tokens → nodes → DOM
譬如假设有这样一个HTML页面:(以下部分的内容出自参考来源,修改了下格式)
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet">
<title>Critical Path</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
</body>
</html>
浏览器的处理如下:
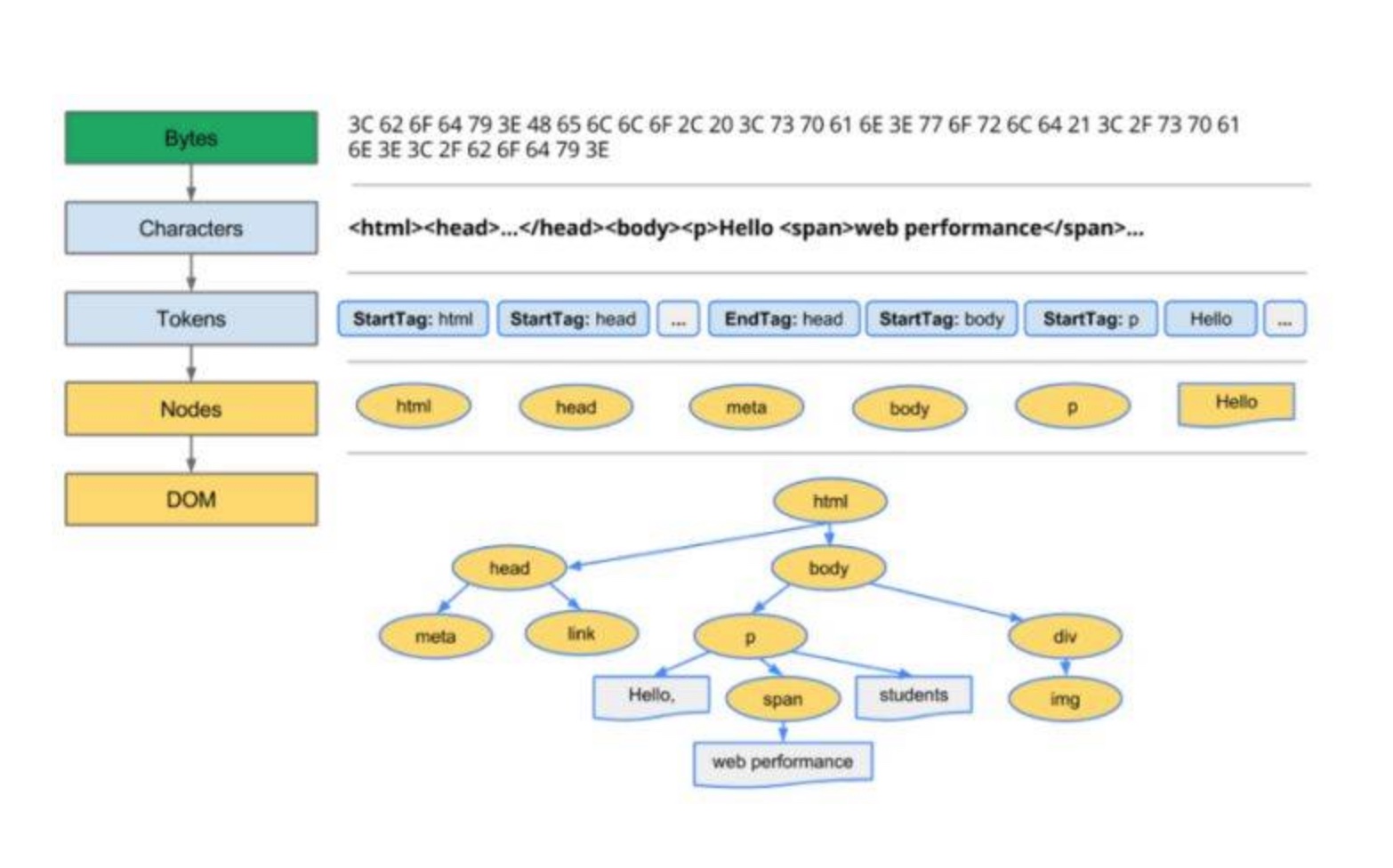
列举其中的一些重点过程:
Conversion转换:浏览器将获得的HTML内容(Bytes)基于他的编码转换为单个字符
Tokenizing分词:浏览器按照HTML规范标准将这些字符转换为不同的标记token。每个token都有自己独特的含义以及规则集
Lexing词法分析:分词的结果是得到一堆的token,此时把他们转换为对象,这些对象分别定义他们的属性和规则
DOM构建:因为HTML标记定义的就是不同标签之间的关系,这个关系就像是一个树形结构一样 例如:body对象的父节点就是HTML对象,然后段略p对象的父节点就是body对象